
《大话数据结构》(线性表)
Chapter 1 数据结构绪论
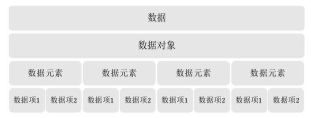
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
数据
数据:是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。
数据元素
数据元素:是组成数据的、有一定意义的基本单位,在计算机中通常作为整体处理。也被称为记录。
数据项
数据项:一个数据元素可以由若干个数据项组成。数据项是数据不可分割的最小单位。
数据对象
数据对象:是性质相同的数据元素的集合,是数据的子集。
数据结构
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。在计算机中,数据元素并不是孤立、杂乱无序的,而是具有内在联系的数据集合。数据元素之间存在的一种或多种特定关系,也就是数据的组织形式。
逻辑结构与物理结构
按照视点的不同,我们把数据结构分为逻辑结构和物理结构。
逻辑结构
逻辑结构:是指数据对象中数据元素之间的相互关系。逻辑结构分为以下四种:
- 1.集合结构
集合结构:集合结构中的数据元素除了同属于一个集合外,它们之间没有其他关系。各个数据元素是“平等”的,它们的共同属性是“同属于一个集合”。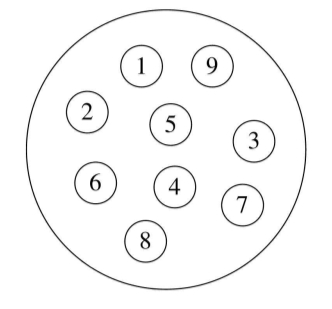
- 2.线性结构
线性结构:线性结构中的数据元素之间是一对一的关系。
- 3.树形结构
树形结构:树形结构中的数据元素之间存在一种一对多的层次关系。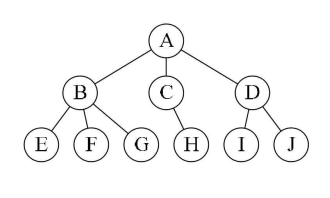
- 4.图形结构
图形结构:图形结构的数据元素是多对多的关系。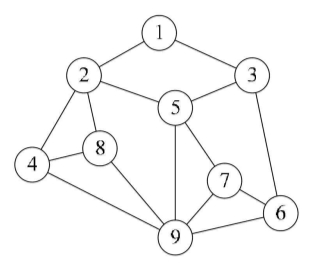
物理结构
物理结构:是指数据的逻辑结构在计算机中的存储形式。
数据元素的存储结构形式有两种:顺序存储和链式存储。
- 1.顺序存储结构
顺序存储结构:是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的。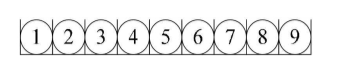
- 2.链式存储结构
链式存储结构:是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的。数据元素的存储关系并不能反映其逻辑关系,因此需要用一个指针存放数据元素的地址,这样通过地址就可以找到相关联数据元素的位置。
抽象数据类型
数据类型
数据类型:是指一组性质相同的值的集合及定义在此集合上的一些操作的总称。
在C语言中,按照取值的不同,数据类型可以分为两类:
- 原子类型:是不可以再分解的基本类型,包括整型、实型、字符型等。
- 结构类型:由若干个类型组合而成,是可以再分解的。例如,整型数组是由若干整型数据组成的。
抽象数据类型
抽象是指抽取出事物具有的普遍性的本质。它是抽出问题的特征而忽略非本质的细节,是对具体事物的一个概括。抽象是一种思考问题的方式,它隐藏了繁杂的细节,只保留实现目标所必需的信息。
抽象数据类型(Abstract Data Type,ADT):是指一个数学模型及定义在该模型上的一组操作。抽象数据类型的定义仅取决于它的一组逻辑特性,而与其在计算机内部如何表示和实现无关。总结

Chapter 2 算法
算法:算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
算法的特性
算法具有五个基本特性:输入、输出、有穷性、确定性和可行性。
输入输出
算法具有零个或多个输入,算法至少有一个或多个输出。
有穷性
有穷性:指算法在执行有限的步骤之后,自动结束而不会出现无限循环,并且每一个步骤在可接受的时间内完成。
确定性
确定性:算法的每一步骤都具有确定的含义,不会出现二义性。算法在一定条件下,只有一条执行路径,相同的输入只能有唯一的输出结果。算法的每个步骤被精确定义而无歧义。
可行性
可行性:算法的每一步都必须是可行的,也就是说,每一步都能够通过执行有限次数完成。
正确性
正确性:算法的正确性是指算法至少应该具有输入、输出和加工处理无歧义性、能正确反映问题的需求、能够得到问题的正确答案。
但是算法的“正确”通常在用法上有很大的差别,大体分为以下四个层次。 1.算法程序没有语法错误。 2.算法程序对于合法的输入数据能够产生满足要求的输出结果。 3.算法程序对于非法的输入数据能够得出满足规格说明的结果。 4.算法程序对于精心选择的,甚至刁难的测试数据都有满足要求的输出结果。
可读性
可读性:算法设计的另一目的是为了便于阅读、理解和交流。
健壮性
健壮性:当输入数据不合法时,算法也能做出相关处理,而不是产生异常或莫名其妙的结果。
时间效率高和存储量低
时间效率指的是算法的执行时间,对于同一个问题,如果有多个算法能够解决,执行时间短的算法效率高,执行时间长的效率低。存储量需求指的是算法在执行过程中需要的最大存储空间,主要指算法程序运行时所占用的内存或外部硬盘存储空间。设计算法应该尽量满足时间效率高和存储量低的需求。
算法效率的度量方法
事后统计方法
事后统计方法:这种方法主要是通过设计好的测试程序和数据,利用计算机计时器对不同算法编制的程序的运行时间进行比较,从而确定算法效率的高低。
事前分析估算方法
事前分析估算方法:在计算机程序编制前,依据统计方法对算法进行估算。
函数的渐进增长
函数的渐近增长:给定两个函数f(n)和g(n),如果存在一个整数N,使得对于所有的n>N,f(n)总是比g(n)大,那么,我们说f(n)的增长渐近快于g(n)。
判断一个算法的效率时,函数中的常数和其他次要项常常可以忽略,而更应该关注主项(最高阶项)的阶数。
算法时间复杂度
算法时间复杂度定义
在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况并确定T(n)的数量级。算法的时间复杂度,也就是算法的时间量度,记作:T(n)=O(f(n))。它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐近时间复杂度,简称为时间复杂度。其中f(n)是问题规模n的某个函数。
推导大O阶方法
推导大O阶:
- 1.用常数1取代运行时间中的所有加法常数。
- 2.在修改后的运行次数函数中,只保留最高阶项。
- 3.如果最高阶项存在且不是1,则去除与这个项相乘的常数。
得到的结果就是大O阶。常数阶
事实上无论n为多少,上面的两段代码就是3次和12次执行的差异。这种与问题的大小无关(n的多少),执行时间恒定的算法,我们称之为具有O(1)的时间复杂度,又叫常数阶。
对于分支结构而言,无论是真,还是假,执行的次数都是恒定的,不会随着n的变大而发生变化,所以单纯的分支结构(不包含在循环结构中),其时间复杂度也是O(1)。线性阶
要确定某个算法的阶次,我们常常需要确定某个特定语句或某个语句集运行的次数。因此,我们要分析算法的复杂度,关键就是要分析循环结构的运行情况。对数阶
由于每次count乘以2之后,就距离n更近了一分。也就是说,有多少个2相乘后大于n,则会退出循环。由2x=n得到x=log2n。所以这个循环的时间复杂度为O(logn)。1
2
3
4
5
6int count = 1;
while (count < n)
{
count = count * 2;
/* 时间复杂度为O(1)的程序步骤序列 */
}平方阶
循环的时间复杂度等于循环体的复杂度乘以该循环运行的次数。常见的时间复杂度
执行次数 函数阶 非正式术语 12 O(1) 常数阶 2n+3 O(n) 线性阶 3n2 +2n+1 O(n2) 平方阶 5log2n+20 O(logn) 对数阶 2n+3nlog2n+19 O(nlogn) nlogn阶 6n3+2n2+3n+4 O(n3 ) 立方阶 2n O(2n) 指数阶
常用的时间复杂度所耗费的时间从小到大依次是:
O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)
最坏情况与平均情况
对算法的分析,一种方法是计算所有情况的平均值,这种时间复杂度的计算方法称为平均时间复杂度。另一种方法是计算最坏情况下的时间复杂度,这种方法称为最坏时间复杂度。一般在没有特殊说明的情况下,都是指最坏时间复杂度。
算法空间复杂度
算法的空间复杂度通过计算算法所需的存储空间实现,算法空间复杂度的计算公式记作:S(n)=O(f(n)),其中,n为问题的规模,f(n)为语句关于n所占存储空间的函数。
线性表
线性表:零个或多个数据元素的有限序列。
线性表的定义
线性表(List):零个或多个数据元素的有限序列。
如果用数学语言来进行定义。可如下:
若将线性表记为(a1,…,ai-1,ai,ai+1,…,an),则表中ai-1领先于ai,ai+1领先于ai,称ai-1是ai的直接前驱元素,ai+1是ai的直接后继元素。当i=1,2,…,n-1时,ai有且仅有一个直接后继,当i=2,3,…,n时,ai有且仅有一个直接前驱。
所以线性表元素的个数n(n≥0)定义为线性表的长度,当n=0时,称为空表。
在非空表中的每个数据元素都有一个确定的位置,如a1是第一个数据元素,an是最后一个数据元素,ai是第i个数据元素,称i为数据元素ai在线性表中的位序。
线性表的抽象数据类型定义如下:
- ADT
线性表(List) - Data
线性表的数据对象集合为{a1, a2, ……, an},每个元素的类型均为DataType。
其中,除第一个元素a1外,每一个元素有且只有一个直接前驱元素,除了最后一个元素an外,每一个元素有且只有一个直接后继元素。
数据元素之间的关系是一对一的关系。 - Operation
InitList(*L): 初始化操作,建立一个空的线性表L。
ListEmpty(L): 若线性表为空,返回true,否则返回false。
ClearList(*L): 将线性表清空。
GetElem(L, i, *e): 将线性表L中的第i个位置元素值返回给e。
LocateElem(L, e): 在线性表L中查找与给定值e相等的元素,如果查找成功,返回该元素在表中序号表示成功;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* 将所有的在线性表Lb中但不在La中的数据元素插入到La中 */
void unionL(List *La, List Lb)
{
int La_len, Lb_len, i;
/* 声明与La和Lb相同的数据元素e */
ElemType e;
/* 求线性表的长度 */
La_len = ListLength(*La);
Lb_len = ListLength(Lb);
for (i = 1; i <= Lb_len; i++)
{
/* 取Lb中第i个数据元素赋给e */
GetElem(Lb, i, &e);
/* La中不存在和e相同数据元素 */
if (!LocateElem(*La, e))
{
/* 插入 */
ListInsert(La, ++La_len, e);
}
}
}线性表的顺序存储结构
顺序存储定义
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。顺序存储方式
线性表的顺序存储的结构代码:描述顺序存储结构需要三个属性:1
2
3
4
5
6
7
8
9
10
11/* 存储空间初始分配量 */
/* ElemType类型根据实际情况而定,这里假设为int */
typedef int ElemType;
typedef struct
{
/* 数组存储数据元素,最大值为MAXSIZE */
ElemType data[MAXSIZE];
/* 线性表当前长度 */
int length;
}SqList; - 存储空间的起始位置:数组data,它的存储位置就是存储空间的存储位置。
- 线性表的最大存储容量:数组长度MaxSize。
- 线性表的当前长度:length。
地址计算方法
用数组存储顺序表意味着要分配固定长度的数组空间,由于线性表中可以进行插入和删除操作,因此分配的数组空间要大于等于当前线性表的长度。
由于每个数据元素,不管它是整型、实型还是字符型,它都是需要占用一定的存储单元空间的。假设占用的是c个存储单元,那么线性表中第i+1个数据元素的存储位置和第i个数据元素的存储位置满足下列关系(LOC表示获得存储位置的函数)。LOC(ai+1)=LOC(ai)+c
所以对于第i个数据元素ai的存储位置可以由a1推算得出:LOC(ai)=LOC(a1)+(i-1)*c
通过这个公式,你可以随时算出线性表中任意位置的地址,不管它是第一个还是最后一个,都是相同的时间。那么我们对每个线性表位置的存入或者取出数据,对于计算机来说都是相等的时间,也就是一个常数,因此用我们算法中学到的时间复杂度的概念来说,它的存取时间性能为O(1)。我们通常把具有这一特点的存储结构称为随机存取结构。
顺序存储结构的插入与删除
获得元素操作
对于线性表的顺序存储结构来说,如果我们要实现GetElem操作,即将线性表L中的第i个位置元素值返回,其实是非常简单的。就程序而言,只要i的数值在数组下标范围内,就是把数组第i-1下标的值返回即可。
1 |
|
插入操作
插入算法的思路:
如果插入位置不合理,抛出异常;
如果线性表长度大于等于数组长度,则抛出异常或动态增加容量;
从最后一个元素开始向前遍历到第i个位置,分别将它们都向后移动一个位置;
将要插入元素填入位置i处;
表长加1。
1 | /* 初始条件:顺序线性表L已存在,1≤i≤ListLength(L), */ |
删除操作
删除算法的思路:
如果删除位置不合理,抛出异常;
取出删除元素;
从删除元素位置开始遍历到最后一个元素位置,分别将它们都向前移动一个位置;
表长减1。
1 | /* 初始条件:顺序线性表L已存在,1≤i≤ListLength(L) */ |
线性表顺序存储结构的优缺点
线性表的顺序存储结构,在存、读数据时,不管是哪个位置,时间复杂度都是O(1);而插入或删除时,时间复杂度都是O(n)。这就说明,它比较适合元素个数不太变化,而更多是存取数据的应用。
线性表的链式存储结构
顺序存储结构不足的解决办法
为什么当插入和删除时,就要移动大量元素,仔细分析后,发现原因就在于相邻两元素的存储位置也具有邻居关系。它们编号是1,2,3,…,n,它们在内存中的位置也是挨着的,中间没有空隙,当然就无法快速介入,而删除后,当中就会留出空隙,自然需要弥补。问题就出在这里。
线性表链式存储结构定义
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置。
以前在顺序结构中,每个数据元素只需要存数据元素信息就可以了。现在链式结构中,除了要存数据元素信息外,还要存储它的后继元素的存储地址。
因此,为了表示每个数据元素ai与其直接后继数据元素ai+1之间的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。
我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
n个结点(ai的存储映像)链结成一个链表,即为线性表(a1,a2,…,an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。单链表正是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起。
对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中第一个结点的存储位置叫做头指针,那么整个链表的存取就必须是从头指针开始进行了。之后的每一个结点,其实就是上一个的后继指针指向的位置。最后一个,当然就意味着直接后继不存在了,所以我们规定,线性链表的最后一个结点指针为“空”。
有时,我们为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。头结点的数据域可以不存储任何信息,也可以存储如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针。
头指针与头结点的异同

线性表链式存储结构代码描述
若线性表为空表,则头结点的指针域为“空”。
单链表中,我们在C语言中可用结构指针来描述:
1 | /* 线性表的单链表存储结构 */ |
从这个结构定义中,我们也就知道,结点由存放数据元素的数据域和存放后继结点地址的指针域组成。假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data来表示,p->data的值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next的值是一个指针。p->next指向谁呢?当然是指向第i+1个元素,即指向ai+1的指针。也就是说,如果p->data=ai,那么p->next->data=ai+1。
单链表的读取
1.声明一个指针p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3.若到链表末尾p为空,则说明第i个结点不存在;
4.否则查找成功,返回结点p的数据。
1 | /* 初始条件:顺序线性表L已存在,1≤i≤ListLength(L) */ |
说白了,就是从头开始找,直到第i个结点为止。由于这个算法的时间复杂度取决于i的位置,当i=1时,则不需遍历,第一个就取出数据了,而当i=n时则遍历n-1次才可以。因此最坏情况的时间复杂度是O(n)。
单链表的插入与删除
单链表的插入
单链表第i个数据插入结点的算法思路:
1.声明一指针p指向链表头结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3.若到链表末尾p为空,则说明第i个结点不存在;
4.否则查找成功,在系统中生成一个空结点s;
5.将数据元素e赋值给s->data;
6.单链表的插入标准语句s->next=p->next;p->next=s;
7.返回成功。
1 | /* 初始条件:顺序线性表L已存在,1≤i≤ListLength(L), */ |
单链表的删除
单链表第i个数据删除结点的算法思路:
1.声明一指针p指向链表头结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1;
3.若到链表末尾p为空,则说明第i个结点不存在;
4.否则查找成功,将欲删除的结点p->next赋值给q;
5.单链表的删除标准语句p->next=q->next;
6.将q结点中的数据赋值给e,作为返回;
7.释放q结点;
8.返回成功。
1 | /* 初始条件:顺序线性表L已存在,1≤i≤ListLength(L) */ |
分析一下刚才我们讲解的单链表插入和删除算法,我们发现,它们其实都是由两部分组成:第一部分就是遍历查找第i个结点;第二部分就是插入和删除结点。
从整个算法来说,我们很容易推导出:它们的时间复杂度都是O(n)。如果在我们不知道第i个结点的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。
但如果,我们希望从第i个位置,插入10个结点,对于顺序存储结构意味着,每一次插入都需要移动n-i个结点,每次都是O(n)。而单链表,我们只需要在第一次时,找到第i个位置的指针,此时为O(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是O(1)。
显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显。
单链表的整表创建
回顾一下,顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。
而单链表和顺序存储结构就不一样,它不像顺序存储结构这么集中,它可以很散,是一种动态结构。对于每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
所以创建单链表的过程就是一个动态生成链表的过程。即从“空表”的初始状态起,依次建立各元素结点,并逐个插入链表。
单链表整表创建的算法思路:
1.声明一指针p和计数器变量i;
2.初始化一空链表L;
3.让L的头结点的指针指向NULL,即建立一个带头结点的单链表;
4.循环:
生成一新结点赋值给p;
随机生成一数字赋值给p的数据域p->data;
将p插入到头结点与前一新结点之间。
- 头插法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* 随机产生n个元素的值,建立带表头结点的单链线性表L(头插法) */
void CreateListHead(LinkList *L, int n)
{
LinkList p;
int i;
/* 初始化随机数种子 */
srand(time(0));
*L = (LinkList)malloc(sizeof(Node));
/* 先建立一个带头结点的单链表 */
(*L)->next = NULL;
for (i = 0; i < n; i++)
{
/* 生成新结点 */
p = (LinkList)malloc(sizeof(Node));
/* 随机生成100以内的数字 */
p->data = rand() % 100 + 1;
p->next = (*L)->next;
/* 插入到表头 */
(*L)->next = p;
}
} - 尾插法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/* 随机产生n个元素的值,建立带表头结点的单链线性表L(尾插法) */
void CreateListTail(LinkList *L, int n)
{
LinkList p,r;
int i;
/* 初始化随机数种子 */
srand(time(0));
/* 为整个线性表 */
*L = (LinkList)malloc(sizeof(Node));
/* r为指向尾部的结点 */
r = *L;
for (i = 0; i < n; i++)
{
/* 生成新结点 */
p = (Node*)malloc(sizeof(Node));
/* 随机生成100以内的数字 */
p->data = rand() % 100 + 1;
/* 将表尾终端结点的指针指向新结点 */
r->next = p;
/* 将当前的新结点定义为表尾终端结点 */
r = p;
}
/* 表示当前链表结束 */
r->next = NULL;
}单链表的整表删除
单链表整表删除的算法思路如下:
1.声明一指针p和q;
2.将第一个结点赋值给p;
3.循环:
将下一结点赋值给q;
释放p;
将q赋值给p。
1 | /* 初始条件:顺序线性表L已存在,操作结果:将L重置为空表 */ |
单链表结构与顺序存储结构优缺点

若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。
若需要频繁插入和删除时,宜采用单链表结构。
比如说游戏开发中,对于用户注册的个人信息,除了注册时插入数据外,绝大多数情况都是读取,所以应该考虑用顺序存储结构。
而游戏中的玩家的武器或者装备列表,随着玩家的游戏过程中,可能会随时增加或删除,此时再用顺序存储就不太合适了,单链表结构就可以大展拳脚。
当然,这只是简单的类比,现实中的软件开发,要考虑的问题会复杂得多。
当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,这样可以不需要考虑存储空间的大小问题。
而如果事先知道线性表的大致长度,比如一年12个月,一周就是星期一至星期日共七天,这种用顺序存储结构效率会高很多。
总之,线性表的顺序存储结构和单链表结构各有其优缺点,不能简单的说哪个好,哪个不好,需要根据实际情况,来综合平衡采用哪种数据结构更能满足和达到需求和性能。
静态链表
首先我们让数组的元素都是由两个数据域组成,data和cur。
也就是说,数组的每个下标都对应一个data和一个cur。
数据域data,用来存放数据元素,也就是通常我们要处理的数据;而cur相当于单链表中的next指针,存放该元素的后继在数组中的下标,我们把cur叫做游标。
我们把这种用数组描述的链表叫做静态链表,这种描述方法还有起名叫做游标实现法。
为了我们方便插入数据,我们通常会把数组建立得大一些,以便有一些空闲空间可以便于插入时不至于溢出。
1 | /* 线性表的静态链表存储结构 */ |
另外我们对数组第一个和最后一个元素作为特殊元素处理,不存数据。
我们通常把未被使用的数组元素称为备用链表。
而数组第一个元素,即下标为0的元素的cur就存放备用链表的第一个结点的下标;而数组的最后一个元素的cur则存放第一个有数值的元素的下标,相当于单链表中的头结点作用,当整个链表为空时,则为0。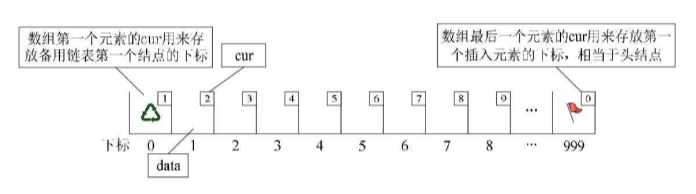
此时“甲”这里就存有下一元素“乙”的游标2,“乙”则存有下一元素“丁”的下标3。而“庚”是最后一个有值元素,所以它的cur设置为0。而最后一个元素的cur则因“甲”是第一有值元素而存有它的下标为1。而第一个元素则因空闲空间的第一个元素下标为7,所以它的cur存有7。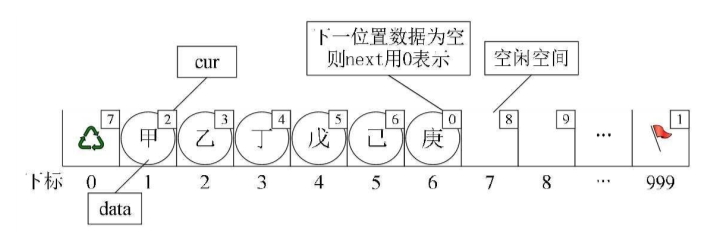
静态链表的插入操作
静态链表中要解决的是:如何用静态模拟动态链表结构的存储空间的分配,需要时申请,无用时释放。
我们前面说过,在动态链表中,结点的申请和释放分别借用malloc()和free()两个函数来实现。
在静态链表中,操作的是数组,不存在像动态链表的结点申请和释放问题,所以我们需要自己实现这两个函数,才可以做插入和删除的操作。
为了辨明数组中哪些分量未被使用,解决的办法是将所有未被使用过的及已被删除的分量用游标链成一个备用的链表,每当进行插入时,便可以从备用链表上取得第一个结点作为待插入的新结点。
1 | /* 若备用空间链表非空,则返回分配的结点下标,否则返回0 */ |
- 插入操作就这样,我们实现了在数组中,实现不移动元素,却插入了数据的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/* 在L中第i个元素之前插入新的数据元素e */
Status ListInsert(StaticLinkList L, int i, ElemType e)
{
int j, k, l;
/* 注意k首先是最后一个元素的下标 */
k = MAX_SIZE - 1;
if (i < 1 || i > ListLength(L) + 1)return ERROR;
/* 获得空闲分量的下标 */
j = Malloc_SSL(L);
if (j)
{
/* 将数据赋值给此分量的data */
L[j].data = e;
/* 找到第i个元素之前的位置 */
for (l = 1; l <= i - 1; l++)
{
k = L[k].cur;
}
/* 把第i个元素之前的cur赋值给新元素的cur */
L[j].cur = L[k].cur;
/* 把新元素的下标赋值给第i个元素之前元素的cur */
L[k].cur = j;
return OK;
}
return ERROR;
}
静态链表的删除操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* 删除在L中第i个数据元素e */
Status ListDelete(StaticLinkList L, int i)
{
int j, k;
if (i < 1 || i > ListLength(L))return ERROR;
k = MAX_SIZE - 1;
for (j = 1; j <= i - 1; j++)
{
k = L[k].cur;
}
j = L[k].cur;// 待删除元素i的索引j
L[k].cur = L[j].cur;
Free_SSL(L, j);
return OK;
} - Free_SSL(L, j)
1
2
3
4
5
6
7
8/* 将下标为k的空闲结点回收到备用链表 */
void Free_SSL(StaticLinkList space, int k)
{
/* 把第一个元素cur值赋给要删除的分量cur */
space[k].cur = space[0].cur;
/* 把要删除的分量下标赋值给第一个元素的cur */
space[0].cur = k;
}
- ListLength
1
2
3
4
5
6
7
8
9
10
11
12/* 初始条件:静态链表L已存在。操作结果:返回L中数据元素个数 */
int ListLength(StaticLinkList L)
{
int j = 0;
int i = L[MAXSIZE - 1].cur;
while (i)
{
i = L[i].cur;
j++;
}
return j;
}静态链表优缺点

顺序储存结构随机存取:顺序存储结构的地址在内存中是连续的所以可以通过计算地址实现随机存取,与此相对 链式存储结构的存储地址不一定连续,只能通过第个结点的指针顺序存取。
总的来说,静态链表其实是为了给没有指针的高级语言设计的一种实现单链表能力的方法。循环链表
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linked list)。
为了使空链表与非空链表处理一致,我们通常设一个头结点,当然,这并不是说,循环链表一定要头结点,这需要注意。
合并两个循环链表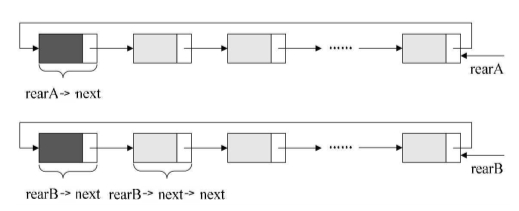
1 | /* 保存A表的头结点*/ |
双向链表
双向链表(double linkedlist)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
1 | /* 线性表的双向链表存储结构 */ |
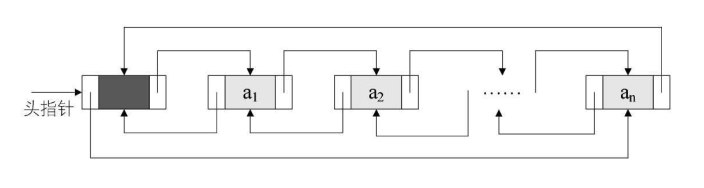
双向链表既然是比单链表多了如可以反向遍历查找等数据结构,那么也就需要付出一些小的代价:在插入和删除时,需要更改两个指针变量。
- 插入操作
插入操作时,其实并不复杂,不过顺序很重要,千万不能写反了。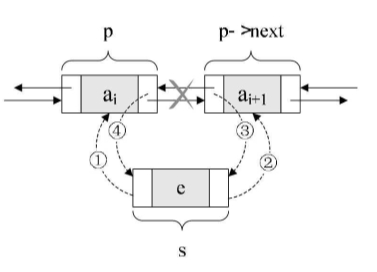
1 | /* 把p赋值给s的前驱,如图中① */ |
- 删除操作
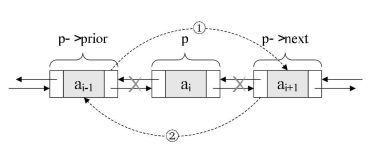
1
2
3
4
5
6/* 把p->next赋值给p->prior的后继,如图中① */
p->prior->next = p->next;
/* 把p->prior赋值给p->next的前驱,如图中② */
p->next->prior = p->prior;
/* 释放结点 */
free(p);总结回顾
先谈了它的定义,线性表是零个或多个具有相同类型的数据元素的有限序列。然后谈了线性表的抽象数据类型,如它的一些基本操作。
之后我们就线性表的两大结构做了讲述,先讲的是比较容易的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。通常我们都是用数组来实现这一结构。
后来是我们的重点,由顺序存储结构的插入和删除操作不方便,引出了链式存储结构。
它具有不受固定的存储空间限制,可以比较快捷的插入和删除操作的特点。
然后我们分别就链式存储结构的不同形式,如单链表、循环链表和双向链表做了讲解,另外我们还讲了若不使用指针如何处理链表结构的静态链表方法。
第四章 栈与队列
栈是限定仅在表尾进行插入和删除操作的线性表。
队列是只允许在一端进行插入操作、而在另一端进行删除操作的线性表。栈的定义
- 栈(stack)是限定仅在表尾进行插入和删除操作的线性表。
我们把允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom),不含任何数据元素的栈称为空栈。栈又称为后进先出(LastIn First Out)的线性表,简称LIFO结构。
- 理解栈的定义需要注意:
首先它是一个线性表,也就是说,栈元素具有线性关系,即前驱后继关系。只不过它是一种特殊的线性表而已。定义中说是在线性表的表尾进行插入和删除操作,这里表尾是指栈顶,而不是栈底。
它的特殊之处就在于限制了这个线性表的插入和删除位置,它始终只在栈顶进行。这也就使得:栈底是固定的,最先进栈的只能在栈底。
栈的插入操作,叫作进栈,也称压栈、入栈。栈的删除操作,叫作出栈,也有的叫作弹栈。
进栈出栈变化形式
这个最先进栈的元素,是不是就只能是最后出栈呢?
答案是不一定,要看什么情况。
栈对线性表的插入和删除的位置进行了限制,并没有对元素进出的时间进行限制,也就是说,在不是所有元素都进栈的情况下,事先进去的元素也可以出栈,只要保证是栈顶元素出栈就可以。
第一种:1、2、3进,再3、2、1出。这是最简单的最好理解的一种,出栈次序为321。
第二种:1进,1出,2进,2出,3进,3出。也就是进一个就出一个,出栈次序为123。
第三种:1进,2进,2出,1出,3进,3出。出栈次序为213。
第四种:1进,1出,2进,3进,3出,2出。出栈次序为132。
第五种:1进,2进,2出,3进,3出,1出。出栈次序为231。
栈的抽象数据类型
ADT 栈(stack)
Data
同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系。
Operation
InitStack(*S): 初始化操作,建立一个空栈S。
DestroyStack(*S): 若栈存在,则销毁它。
ClearStack(*S): 将栈清空。
StackEmpty(S): 若栈为空,返回true,否则返回false。
GetTop(S, *e): 若栈存在且非空,用e返回S的栈顶元素。
Push(*S, e): 若栈S存在,插入新元素e到栈S中并成为栈顶元素。
Pop(*S, *e): 删除栈S中栈顶元素,并用e返回其值。
StackLength(S): 返回栈S的元素个数。
endADT
由于栈本身就是一个线性表,那么上一章我们讨论了线性表的顺序存储和链式存储,对于栈来说,也是同样适用的。
栈的顺序存储结构及实现
既然栈是线性表的特例,那么栈的顺序存储其实也是线性表顺序存储的简化,我们简称为顺序栈。线性表是用数组来实现的,想想看,对于栈这种只能一头插入删除的线性表来说,用数组哪一端来作为栈顶和栈底比较好?
对,没错,下标为0的一端作为栈底比较好,因为首元素都存在栈底,变化最小,所以让它作栈底。
栈的结构定义
1 | /* SElemType类型根据实际情况而定,这里假设为int */ |
栈的顺序存储结构——进栈操作(push)
1 | /* 插入元素e为新的栈顶元素 */ |
栈的顺序存储结构——出栈(pop)
1 | /* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */ |
两者没有涉及到任何循环语句,因此时间复杂度均是O(1)。
两栈共享空间
其实栈的顺序存储还是很方便的,因为它只准栈顶进出元素,所以不存在线性表插入和删除时需要移动元素的问题。
不过它有一个很大的缺陷,就是必须事先确定数组存储空间大小,万一不够用了,就需要编程手段来扩展数组的容量,非常麻烦。
对于一个栈,我们也只能尽量考虑周全,设计出合适大小的数组来处理,但对于两个相同类型的栈,我们却可以做到最大限度地利用其事先开辟的存储空间来进行操作。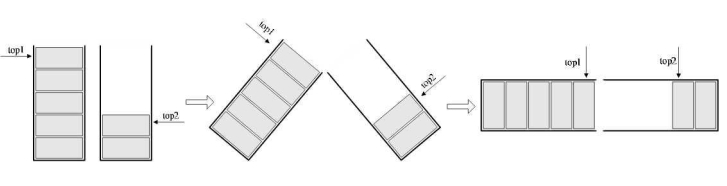
其实关键思路是:它们是在数组的两端,向中间靠拢。top1和top2是栈1和栈2的栈顶指针,可以想象,只要它们俩不见面,两个栈就可以一直使用。
1 | /* 两栈共享空间结构 */ |
对于两栈共享空间的push方法,我们除了要插入元素值参数外,还需要有一个判断是栈1还是栈2的栈号参数stackNumber。
1 | /* 插入元素e为新的栈顶元素 */ |
对于两栈共享空间的pop方法,参数就只是判断栈1栈2的参数stackNumber。
1 | /* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */ |
栈的链式存储结构及实现
栈的链式存储结构,简称为链栈。
想想看,栈只是栈顶来做插入和删除操作,栈顶放在链表的头部还是尾部呢?由于单链表有头指针,而栈顶指针也是必须的,那干吗不让它俩合二为一呢,所以比较好的办法是把栈顶放在单链表的头部(如图4-6-1所示)。另外,都已经有了栈顶在头部了,单链表中比较常用的头结点也就失去了意义,通常对于链栈来说,是不需要头结点的。
对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是top=NULL的时候。
链栈的结构代码如下:
1 | typedef struct StackNode |
链栈的操作绝大部分都和单链表类似,只是在插入和删除上,特殊一些。
栈的链式存储结构——进栈操作
1 | /* 插入元素e为新的栈顶元素 */ |
栈的链式存储结构——出栈操作
1 | /* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */ |
链栈的进栈push和出栈pop操作都很简单,没有任何循环操作,时间复杂度均为O(1)。
对比一下顺序栈与链栈,它们在时间复杂度上是一样的,均为O(1)。
对于空间性能,顺序栈需要事先确定一个固定的长度,可能会存在内存空间浪费的问题,但它的优势是存取时定位很方便,而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。
所以它们的区别和线性表中讨论的一样,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
栈的作用
栈的引入简化了程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于我们要解决的问题核心。反之,像数组等,因为要分散精力去考虑数组的下标增减等细节问题,反而掩盖了问题的本质。
栈的应用——递归
递归定义
在高级语言中,调用自己和其他函数并没有本质的不同。我们把一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称做递归函数。
当然,写递归程序最怕的就是陷入永不结束的无穷递归中,所以,每个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出。
迭代和递归的区别是:迭代使用的是循环结构,递归使用的是选择结构。
递归能使程序的结构更清晰、更简洁、更容易让人理解,从而减少读懂代码的时间。但是大量的递归调用会建立函数的副本,会耗费大量的时间和内存。
迭代则不需要反复调用函数和占用额外的内存。
因此我们应该视不同情况选择不同的代码实现方式。
那么我们讲了这么多递归的内容,和栈有什么关系呢?这得从计算机系统的内部说起。
前面我们已经看到递归是如何执行它的前行和退回阶段的。
递归过程退回的顺序是它前行顺序的逆序。
在退回过程中,可能要执行某些动作,包括恢复在前行过程中存储起来的某些数据。
这种存储某些数据,并在后面又以存储的逆序恢复这些数据,以提供之后使用的需求,显然很符合栈这样的数据结构,因此,编译器使用栈实现递归就没什么好惊讶的了。
简单的说,就是在前行阶段,对于每一层递归,函数的局部变量、参数值以及返回地址都被压入栈中。
在退回阶段,位于栈顶的局部变量、参数值和返回地址被弹出,用于返回调用层次中执行代码的其余部分,也就是恢复了调用的状态。
当然,对于现在的高级语言,这样的递归问题是不需要用户来管理这个栈的,一切都由系统代劳了。
栈的应用——四则运算表达式求值
后缀(逆波兰)表示法定义
如果让你用C语言或其他高级语言实现对数学表达式的求值,你打算如何做?
这里面的困难就在于乘除在加减的后面,却要先运算,而加入了括号后,就变得更加复杂。不知道该如何处理。
但仔细观察后发现,括号都是成对出现的,有左括号就一定会有右括号,对于多重括号,最终也是完全嵌套匹配的。
这用栈结构正好合适,只要碰到左括号,就将此左括号进栈,不管表达式有多少重括号,反正遇到左括号就进栈,而后面出现右括号时,就让栈顶的左括号出栈,期间让数字运算,这样,最终有括号的表达式从左到右巡查一遍,栈应该是由空到有元素,最终再因全部匹配成功后成为空栈。
但对于四则运算,括号也只是当中的一部分,先乘除后加减使得问题依然复杂,如何有效地处理它们呢?我们伟大的科学家想到了好办法。
- 后缀(逆波兰)表示法定义
对于“9+(3-1)×3+10÷2”,如果要用后缀表示法应该是什么样子:“9 3 1-3*+102/+”,这样的表达式称为后缀表达式,叫后缀的原因在于所有的符号都是在要运算数字的后面出现。显然,这里没有了括号。
后缀表达式计算结果
9+(3-1)×3+10÷2
后缀表达式:9 3 1-3*+10 2/+
规则:从左到右遍历表达式的每个数字和符号,遇到是数字就进栈,遇到是符号,就将处于栈顶两个数字出栈,进行运算,运算结果进栈,一直到最终获得结果。
1.初始化一个空栈。此栈用来对要运算的数字进出使用。
2.后缀表达式中前三个都是数字,所以9、3、1进栈。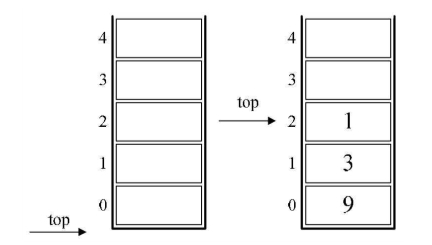
3.接下来是“-”,所以将栈中的1出栈作为减数,3出栈作为被减数,并运算3-1得到2,再将2进栈。
4.接着是数字3进栈。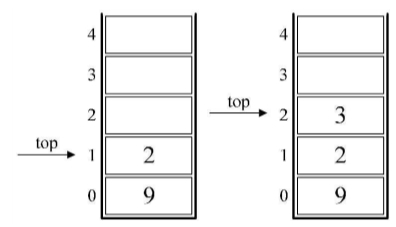
5.后面是“*”,也就意味着栈中3和2出栈,2与3相乘,得到6,并将6进栈。
6.下面是“+”,所以栈中6和9出栈,9与6相加,得到15,将15进栈。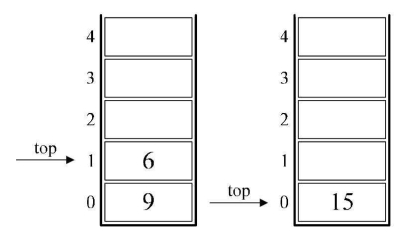
7.接着是10与2两数字进栈。
8.接下来是符号“/”,因此,栈顶的2与10出栈,10与2相除,得到5,将5进栈。
9.最后一个是符号“+”,所以15与5出栈并相加,得到20,将20进栈。
10.结果是20出栈,栈变为空。
中缀表达式转后缀表达式
我们把平时所用的标准四则运算表达式,即“9+(3-1)×3+10÷2”叫做中缀表达式。因为所有的运算符号都在两数字的中间,现在我们的问题就是中缀到后缀的转化。
中缀表达式“9+(3-1)×3+10÷2”转化为后缀表达式“9 3 1-3*+10 2/+”。
规则:
从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;
若是符号,则判断其与栈顶符号的优先级,是右括号或优先级不高于栈顶符号(乘除优先加减)则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止。
1.初始化一空栈,用来对符号进出栈使用。
2.第一个字符是数字9,输出9,后面是符号“+”,进栈。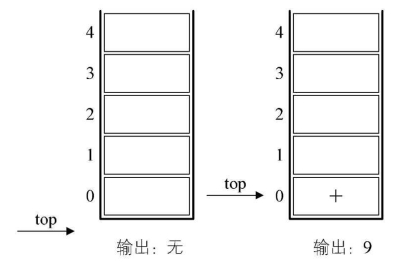
3.第三个字符是“(”,依然是符号,因其只是左括号,还未配对,故进栈。
4.第四个字符是数字3,输出,总表达式为93,接着是“-”,进栈。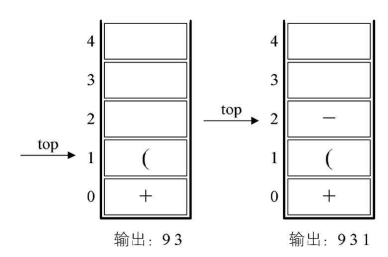
5.接下来是数字1,输出,总表达式为 9 31,后面是符号“)”,此时,我们需要去匹配此前的“(”,所以栈顶依次出栈,并输出,直到“(”出栈为止。此时左括号上方只有“-”,因此输出“-”。总的输出表达式为 9 3 1-。
6.紧接着是符号“×”,因为此时的栈顶符号为“+”号,优先级低于“×”,因此不输出,“*”进栈。接着是数字3,输出,总的表达式为 9 3 1-3。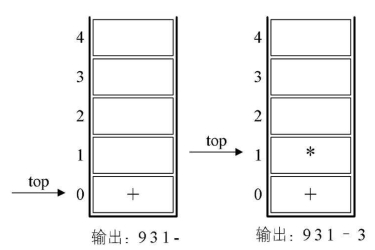
7.之后是符号“+”,此时当前栈顶元素“ * ”比这个“+”的优先级高,因此栈中元素出栈并输出(没有比“+”号更低的优先级,所以全部出栈),总输出表达式为9 3 1-3 *+。然后将当前这个符号“+”进栈。也就是说,前6张图的栈底的“+”是指中缀表达式中开头的9后面那个“+”,而图4-9-9左图中的栈底(也是栈顶)的“+”是指“9+(3-1)×3+”中的最后一个“+”。
8.紧接着数字10,输出,总表达式变为9 31-3 *+10。后是符号“÷”,所以“/”进栈。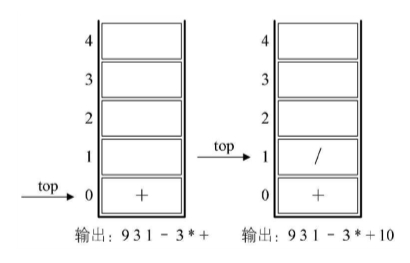
9.最后一个数字2,输出,总的表达式为9 31-3+10 2。
10.因已经到最后,所以将栈中符号全部出栈并输出。最终输出的后缀表达式结果为93 1-3+10 2/+。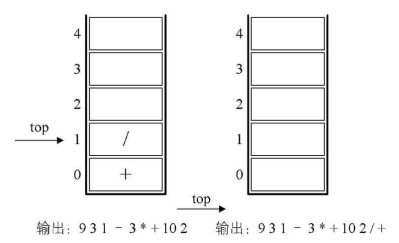
从刚才的推导中你会发现,要想让计算机具有处理我们通常的标准(中缀)表达式的能力,最重要的就是两步: 1.将中缀表达式转化为后缀表达式(栈用来进出运算的符号)。 2.将后缀表达式进行运算得出结果(栈用来进出运算的数字)。
队列
队列的定义
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头。
队列的抽象数据类型
同样是线性表,队列也有类似线性表的各种操作,不同的就是插入数据只能在队尾进行,删除数据只能在队头进行。
ADT 队列(Queue)
Data 同线性表。
元素具有相同的类型,相邻元素具有前驱和后继关系。
Operation
InitQueue(*Q): 初始化操作,建立一个空队列Q。
DestroyQueue(*Q): 若队列Q存在,则销毁它。
ClearQueue(*Q): 将队列Q清空。
QueueEmpty(Q): 若队列Q为空,返回true,否则返回false。
GetHead(Q, *e): 若队列Q存在且非空,用e返回队列Q的队头元素。
EnQueue(*Q, e): 若队列Q存在,插入新元素e到队列Q中并成为队尾元素。
DeQueue(*Q, *e): 删除队列Q中队头元素,并用e返回其值。
QueueLength(Q): 返回队列Q的元素个数
endADT
循环队列
线性表有顺序存储和链式存储,栈是线性表,所以有这两种存储方式。同样,队列作为一种特殊的线性表,也同样存在这两种存储方式。我们先来看队列的顺序存储结构。
队列顺序存储的不足
我们假设一个队列有n个元素,则顺序存储的队列需建立一个大于n的数组,并把队列的所有元素存储在数组的前n个单元,数组下标为0的一端即是队头。所谓的入队列操作,其实就是在队尾追加一个元素,不需要移动任何元素,因此时间复杂度为O(1)。
与栈不同的是,队列元素的出列是在队头,即下标为0的位置,那也就意味着,队列中的所有元素都得向前移动,以保证队列的队头,也就是下标为0的位置不为空,此时时间复杂度为O(n)。
循环队列定义
所以解决假溢出的办法就是后面满了,就再从头开始,也就是头尾相接的循环。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
通用的计算队列长度公式为:(rear-front+QueueSize)%QueueSize。
循环队列的顺序存储结构代码如下:
1 | /* QElemType类型根据实际情况而定,这里假设为int */ |
循环队列的初始化代码如下:
1 | /* 初始化一个空队列Q */ |
循环队列求队列长度代码如下:
1 | /* 返回Q的元素个数,也就是队列的当前长度 */ |
循环队列的入队列操作代码如下:
1 | /* 若队列未满,则插入元素e为Q新的队尾元素 */ |
循环队列的出队列操作代码如下:
1 | /* 若队列不空,则删除Q中队头元素,用e返回其值 */ |
队列的链式存储结构及实现
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出而已,我们把它简称为链队列。
为了操作上的方便,我们将队头指针指向链队列的头结点,而队尾指针指向终端结点。
链队列的结构为:
1 | /* QElemType类型根据实际情况而定,这里假设为int */ |
队列的链式存储结构——入队操作:
1 | /* 插入元素e为Q的新的队尾元素 */ |
队列的链式存储结构——出队操作:
1 | /* 若队列不空,删除Q的队头元素,用e返回其值,并返回OK,否则返回ERROR */ |
对于循环队列与链队列的比较,可以从两方面来考虑,从时间上,其实它们的基本操作都是常数时间,即都为O(1)的,不过循环队列是事先申请好空间,使用期间不释放,而对于链队列,每次申请和释放结点也会存在一些时间开销,如果入队出队频繁,则两者还是有细微差异。
对于空间上来说,循环队列必须有一个固定的长度,所以就有了存储元素个数和空间浪费的问题。
而链队列不存在这个问题,尽管它需要一个指针域,会产生一些空间上的开销,但也可以接受。所以在空间上,链队列更加灵活。
总的来说,在可以确定队列长度最大值的情况下,建议用循环队列,如果你无法预估队列的长度时,则用链队列。
总结回顾
我们这一章讲的是栈和队列,它们都是特殊的线性表,只不过对插入和删除操作做了限制。
栈(stack)是限定仅在表尾进行插入和删除操作的线性表。
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
它们均可以用线性表的顺序存储结构来实现,但都存在着顺序存储的一些弊端。因此它们各自有各自的技巧来解决这个问题。
对于栈来说,如果是两个相同数据类型的栈,则可以用数组的两端作栈底的方法来让两个栈共享数据,这就可以最大化地利用数组的空间。
对于队列来说,为了避免数组插入和删除时需要移动数据,于是就引入了循环队列,使得队头和队尾可以在数组中循环变化。解决了移动数据的时间损耗,使得本来插入和删除是O(n)的时间复杂度变成了O(1)。
它们也都可以通过链式存储结构来实现,实现原则上与线性表基本相同。





