
Unity性能优化
LOD层级细节技术
LOD
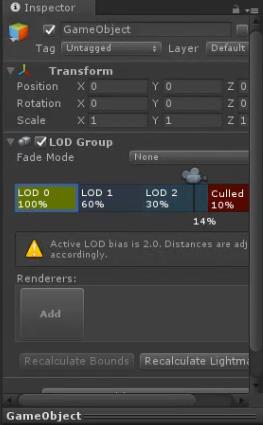
通过不同的距离 显示不同精细程度的模型
OcclusionCulling 遮挡剔除

只显示视野内的物体
光照贴图LightMapping
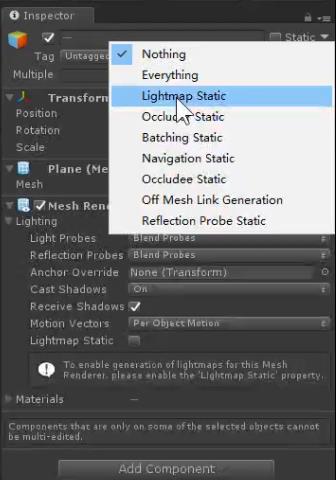
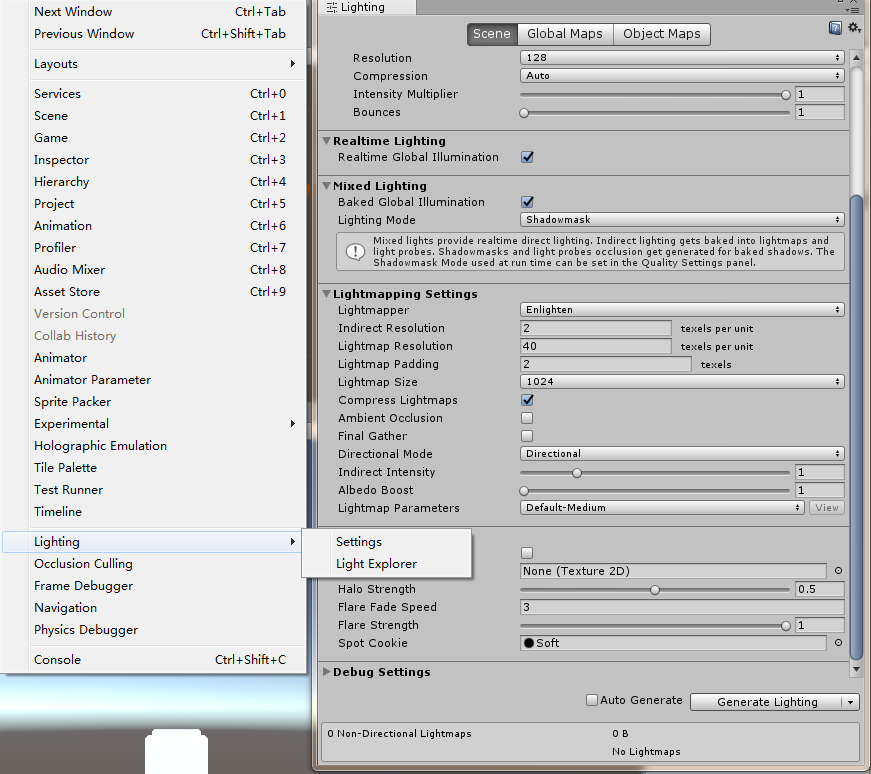
手动烘焙 将光照的Mode设置为Baked
合并Mesh
资源优化标准
资源优化标准
Mesh
动态模型:面片数<3000
材质数<3
骨骼数<50
静态模型
顶点数<500
Audio
长时间音乐(背景音乐)压缩格式 mp3
短时间音乐(音效)非压缩格式 wav
http://blog.csdn.net/u012565990/article/details/51794486
Texture
贴图长宽<1024
Shader
尽量减少复杂数学运算
减少discard操作
模型优化
贴图优化
如何减少冗余资源和重复资源
A、Resources目录下的资源不管是否被引用,都会打包进安装包,不使用的资源不要放在Resources目录下
B、不同目录下的相同资源文件,如果都被引用,那么都会打包进资源包,造成冗余,保证同一个资源文件在项目中只存放在一个目录位置
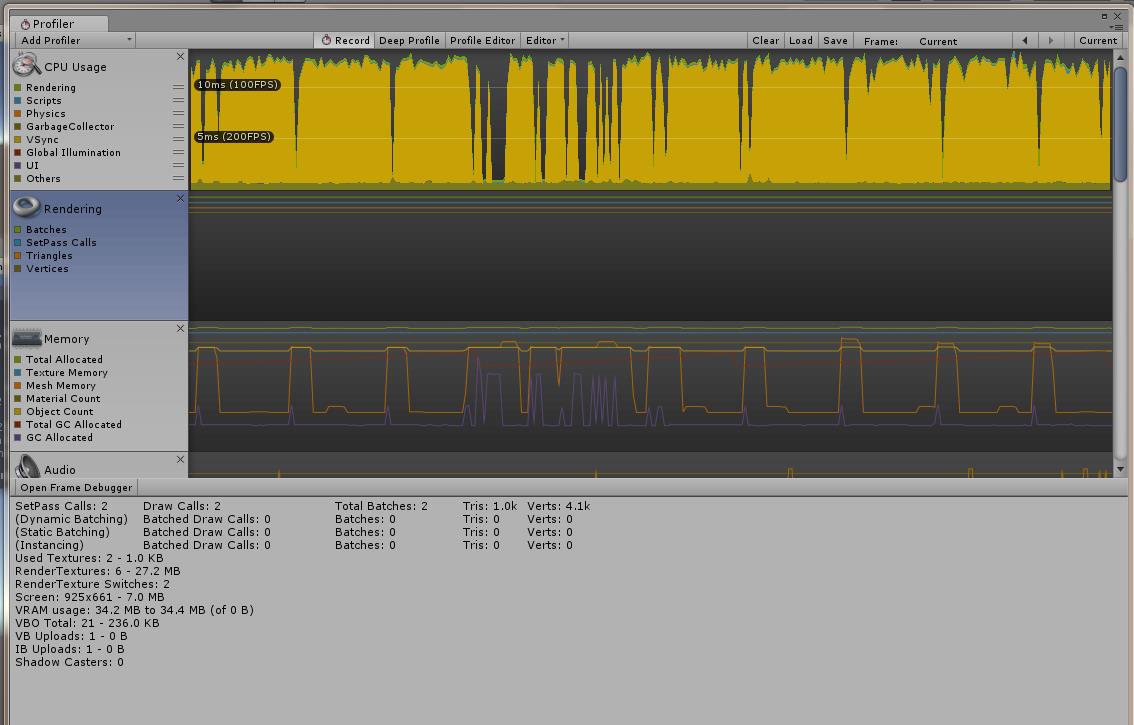
Unity Statistics统计面板
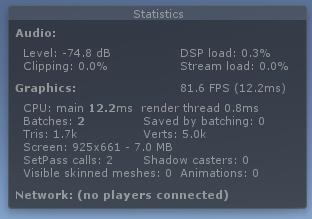
- FPS帧数 当前一秒钟能渲染81.6帧 渲染一帧需要12.2ms(大于30帧人肉眼不会觉得卡顿)
- CPU:main 计算每一帧需要耗费的时间
- render thread 渲染线程
- Batches:批处理次数
- Verts : 顶点个数(相机视野内)
- Tris : 三角面个数(相机视野内)
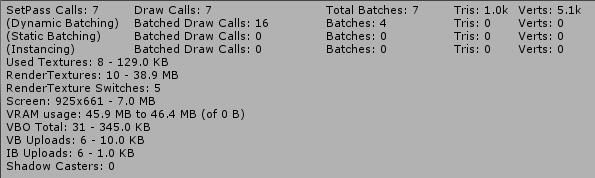
- Batched DrawCall 合并前的DrawCall数量 Batches 合并后的DrawCall数量
- SetPass Calls:shader里面的Pass块
什么是DrawCall
Unity安装包大/运行卡的原因
Unity内置Mono虚拟机让代码可以跨平台运行。
什么是DrawCall
DrawCall很简单,就是cpu对图形绘制接口的调用,CPU通过调用图形库(directx/opengl)接口,命令GPU进行渲染操作。
CPU和GPU是如何进行并行工作和交互的?
试想,渲染流程没用采用流水线的工作方式:CPU发送一个渲染命令之后,GPU立即执行渲染命令绘制图形,等到渲染任务结束之后,CPU才可以继续发送下一个渲染命令,这样显然影响工作效率。
采用渲染流水线后,CPU与GPU并行工作,独立而不相互依赖。这是通过命令缓冲区来实现的:命令缓冲区维护一个命令队列,CPU向其中发送命令,GPU从中取出命令并执行。命令有很多种,DrawCall是一种,其他命令还有改变渲染状态、设置渲染数据流等。
这种方式就类似于游戏开发的网络通信:维持一个消息队列,网络线程接收解析消息并将之添加到消息队列,游戏主线程更新时从中取出消息并做派发处理。
DrawCall是如何影响性能的?
每一次绘制CPU都要调用DrawCall,而在调动DrawCall前,CPU还要进行很多准备工作:检测渲染状态、提交渲染所需要的数据、提交渲染所需要的状态。
而GPU本身具有很强大的计算能力,可以很快就处理完渲染任务。
当DrawCall过多,CPU就会很多额外开销用于准备工作,CPU本身负载,而这时GPU可能闲置了。
DrawCall优化:减少DrawCall
既然,我们已经知道DrawCall导致的性能问题在于DrawCall数量过多,那么我们优化的思路就是减少DrawCall。这里我们只讨论批处理(Batching)。
过多的DrawCall会造成CPU的性能瓶颈:大量时间消耗在DrawCall准备工作上。很显然的一个优化方向就是:尽量把小的DrawCall合并到一个大的DrawCall中,这就是批处理的思想。
使用批处理我们需要在CPU和RAM中合并网格,而合并网格本身是需要计算消耗,而且创建新网格也会占用内存。因此批处理的频次不宜太高,不然造成的消耗可能得不偿失。
使用批处理的注意事项:
- 合并的网格会在一次渲染任务中进行绘制,他们的渲染数据,渲染状态和shader都是一样的,因此合并的条件至少是:同材质、同贴图、同shader。最好网格顶点格式也一致。
- 尽量避免使用大量小的网格,当确实需要时,考虑是否要合并。
- 避免使用过多的材质,尽量共享材质。
- 网格合并的顶点数量有上限(Unity中好像是65535)
- 合并本身有消耗,因此尽量在编辑器下进行合并
- 确实需要在运行时合并的,将静态的物体和动态的物体分开合并:静态的合并一次就可以,动态的只要有物体发生变换就要重新合并。
解决UI卡顿问题
Canvas优化要点
1.Unity为了性能优化会合并Canvas下所有元素。
2.如果把所有面板都放入一个Canvas下,会造成重绘。
- 一个Canvas下的所有UI元素都是合在一个Mesh中的,过大的Mesh在更新时开销很大。
- 一般建议每个较复杂的UI界面,都自成一个Canvas(可以是子Canvas),在UI界面很复杂时,甚至要划分更多的子Canvas。
- 动静分离
- Canvas又不能细分的太多,因为会导致DrawCall的上升
- 把一个面板的UI资源放到一个图集里(背景大图不要和小图放在一个图集里)
Overdraw(GPU)
造成GPU性能瓶颈的主要原因:
- 复杂的vertext或pixel shader计算
- Overdraw:
光栅化阶段的填充像素过多
在UGUI中使用Alpha=0的不可见image参与Raycast,比如在屏幕空白处点击的响应,然而这些元素虽然在屏幕上不可见、但依然参与了绘制!
解决方案举例: - 禁用不可见的UI
比如当打开一个系统时如果完全挡住了另外一个系统,则可以将被遮挡住的系统禁用。 - 不要使用空的image
在unity中,RayCast使用Graphic作为基本元素来检测touch,使用空的image并将alpha设置为0来接收touch事件会产生不必要的overdraw
【内存优化】图集整理策略
游戏开发,肯定会有一堆的图片,游戏运行时,unity会把小图整合到1张大图上,方便渲染合批,降低渲染消耗。
但是,随着游戏开发的进行,图片越来越多,我们总不能所有的图片都塞进这张大图里,那加载的时候,更新的时候,这张大图的加载速度就会超级慢,严重影响游戏体验。这就涉及到图集的整理问题。
优化的本质就是不渲染或少渲染或用更省的方法渲染。
1.Sprite Packer介绍
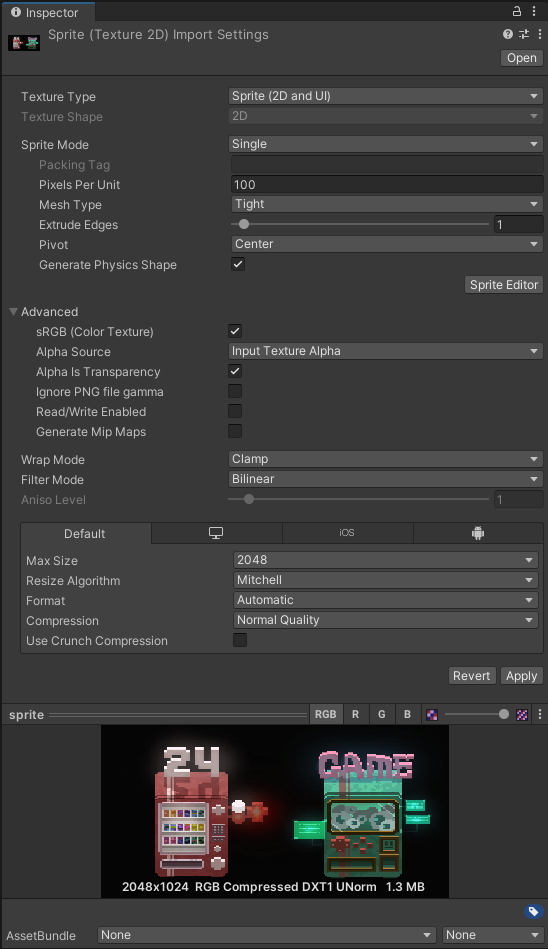
Sprite Packer会把相同Packing Tag以及相同压缩格式的资源打到相同的图集里面。
所以影响图集大小主要集中在2个方面:
- Packing Tag:图集名称
- 资源的压缩格式(format):安卓使用ETC1压缩,IOS默认使用PVRTC,选用不用压缩模式的2张图,即使是同一个Packing Tag,也会被打到2张不同的图集里面。
2. 图集整理策略
知道了Sprite Packer怎么打包图集的,我们就要根据项目实际情况,去合理安排和整理图片资源,图集太大不行,太空也不行,然后又要关心业务,很多注意事项。
所以整理以下几个我们平时整理图集时候会关注的几个点:
- 尽量紧凑,没有太多空白。比如一个图集512x512刚好塞满,现在额外加一张小图进去,就被迫变成512x1024,浪费的空间就很多了,而且在有的平台,该图集会被强制变成1024*1024,内存消耗从1M变成4M。
- Draw Call尽量少,同一个界面的小图尽量在一个图集里。
- 内存管理方便,加载性能好,打开一个界面时只加载必要的图集,关闭时可以方便地释放图集。
- AssetBundle打包\热更粒度合理,不能出现“热更一个新界面,大量图集都需要热更”的情况。
- 维护方便,当界面变化时,调整方便,包括生成图集、调整引用、新图集尺寸变化的影响、新图集AssetBundle变化的影响等等。
- 图集间隙尽量少,主要靠图集工具,常见的比如更紧凑的多边形Mesh替代Rect Mesh、旋转、切割等等。【TP比Unity的 Spirte Packer算法更好,这里我们不讨论】
3. 我们现在项目的图集整理策略:
- 【脚本】按业务功能的预制,寻找依赖,收集所有预制引用的图片,
- 【脚本】将依赖的图片分别移动到对应业务命名的文件夹下【没有就创建】,如果有多个预制使用了同一张图片,我们就把它扔到common文件夹;
- 【人工】打开Spirte Packer,查看图集情况是否合理,合并零碎文件夹,让图集尽量紧凑,没有太多空白,尽量让图集处于2的n次方大小。
- 细碎图片扔进common。
- 程序来管理图集,就导致出包前,老是要要求美术缩小图片啊,调整目录啊,美术也不高兴,我觉得应该将这件事交给美术去做,拉美术一个人负责这件事,这样,他们上传的时候就会注意图片的通道RGBA啊,然后图集分配是否合理这些事,这样我们检查后的反馈就会少很多,大家合作也更舒服。
4.Unity上手动查看这些打包的大图方式:
- 打开 Sprite Packer界面【Window-Sprite Packer(2018版本:Window-2D-Sprite Packer)】
- 点击pack按钮【前提是已经设置了图片的Tag】
- 但是由于unity内置的查看图集很不友好,提供一个工具Altas Looker,可以按上下键看图集,挺方便的。(https://github.com/Aver58/Tools/tree/master/UnityProject/Assets/Editor/AtlasLooker)
5. 资源优化
纹理优化
纹理优化的目的是让它们占用的内存尽量的小,那么纹理加载进内存后,大小计算公式如下:
纹理内存大小(字节) = 纹理宽度 x 纹理高度 x 像素字节
像素字节 = 像素通道数(R/G/B/A) x 通道大小(1字节/半字节)
纹理尺寸
根据项目实际情况将贴图都缩小至合适的大小。这里的合适大小是指渲染对象在画面中大多数情况下不可能达到的最大尺寸,这个尺寸最好保持2的N次方。
纹理通道
通道优化的目的是降低像素所占的大小,可以通过以下方法达到目的:
- 去除Alpha通道。可以减少通道数量,适用于不需要Alpha混合或Alpha Test的角色和物件
- 应用单通道图。也可以减少通道数量,比如灰度图、地形高度图,掩码图,Shader掩码图等
- 使用16位代替32位图。例如RGB444/RGBA4444就可以减少像素通道大小。
提高纹理复用率
- 建立共享图库。将通用的元素放至共享库,例如按钮/进度条/背景/UI通用元素等。
- 用九宫格图代替大块背景图。九宫格在游戏开发中是比较常见的UI组件。
- 纹理元素通过变换可组合成复合纹理。例下图,上下左右对称的背景图可以用4张相同贴图实例通过旋转/翻转后获得。【mirror】
UI图集
界面A引用界面A图集和共享图集是允许的,但尽量不要引用界面B等其它图集。
但实际在游戏开发过程中,很难保证美术做到这一点,通常存在以下问题:
如果界面A确实要用到界面B图集的某个元素,怎么办?
参考解决方法:要看被引用元素的通用度,如果只是界面A和B在用,可以将被引用元素拷贝到界面A图集下;如果其它界面也会引用到,就可以将它移到共享图库。
有些UI纹理很大且很多界面都有用到,如果放在共享图库会导致共享图库急剧膨胀,怎么办?
参考解决方法:大尺寸纹理建议用九宫格+细节图,或通过组合的方式来代替。
如何保证美术制作的UI只引用到自身图集和共享图集?
参考解决方法:实现批处理检查工具,找出每个UI界面引用到的图集列表,引用的图集超过2个便是不合格。
拓展
几种主流贴图压缩算法的实现原理详解
- ETC
ETC压缩算法采用将图像中的chromatic和luminance分开存储的方式,而在解码时使用luminance对chromatic进行调制进而重现原始图像信息。
ETC也主要有两种方法:ETC1和改进后的ETC2。
ETC1:
采用4x2的block进行分割(原始为4*2*24=192,压缩后为32,压缩率为6)。
ETC2:
根据ETC1的实现方式,如果其块内的颜色分布不均匀的话,则其存储的两个basecolor会较远的分布于插值趋线的较远的两侧,进行解压后会得到较低的压缩质量,因而ETC2就是解决如何针对这些较为特殊的颜色分布来选择更加优化的压缩策略。
- PVRTC
PVRTC的不是基于block的方式生成的,但是却也可以理解为以block方式组织的。
- ASTC
ASTC中ARM研发的一种较新的贴图压缩格式,相对于上述几种方法具有较多的优势,其应该会慢慢成为之后移动设备上贴图压缩的主要标准和主流。其主要具有如下的特性:
- 较高的灵活性;
- 可变的压缩率;
- 支持2d/3d贴图;
- 适用于移动平台;
- 支持LDR/HDR贴图内容;
ASTC同样是基于block的压缩方式,但块的大小却较支持多种尺寸,比如从基本的4x4到12x12,而且块的宽高也不限于pot,比如6x5;每个块内的内容用128bits来进行存储,因而不同的块就对应着不同的压缩率。

